Commonly used tasks and Blockly Unix solutions
-
Calculate Average Sales from a CSV File
You have a CSV file (sales.csv) with columns: Date,Region,Sales. You want to calculate the average sales.
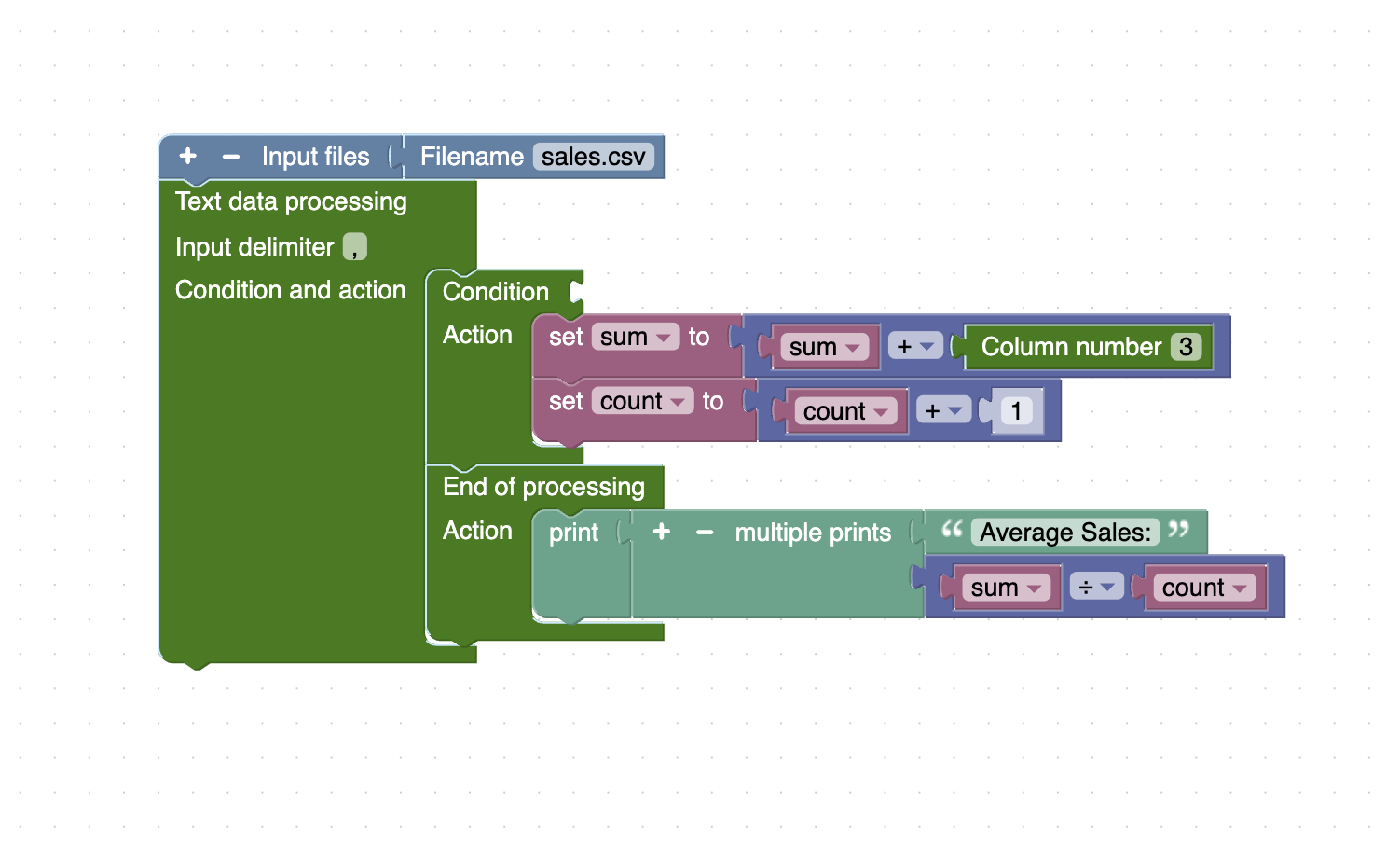
The corresponding Unix command for this task is: awk -F ',' ' {sum = sum + $3; count = count + 1; } END {print "Average Sales:", sum / count; } ' sales.csv
-
Removing Duplicate Lines and Sorting
Remove duplicate lines from a file and then sort the remaining lines.
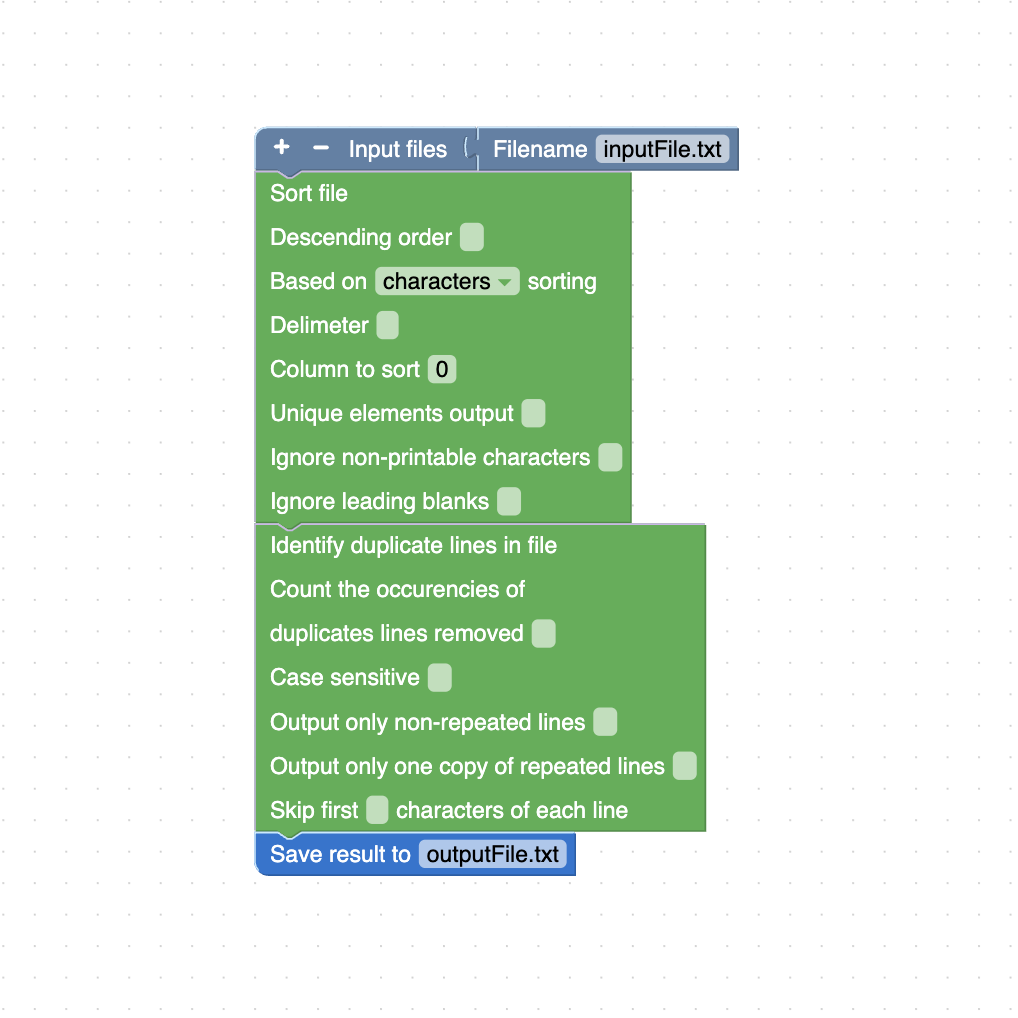
The corresponding Unix command for this task is: sort inputFile.txt | uniq > outputFile.txt
-
Extract, Count, and Save Top Domain Names from a List of URLs
Extract and count domain names from a list of URLs and save the top 15 most frequent domains to a new file.

The corresponding Unix command for this task is: awk -F '/' ' {print $3; } ' url.txt | sort | uniq -c | sort -r | head -n 15 > topDomains.txt
-
Combining Multiple Files into One
Concatenate the contents of multiple files into a single file.
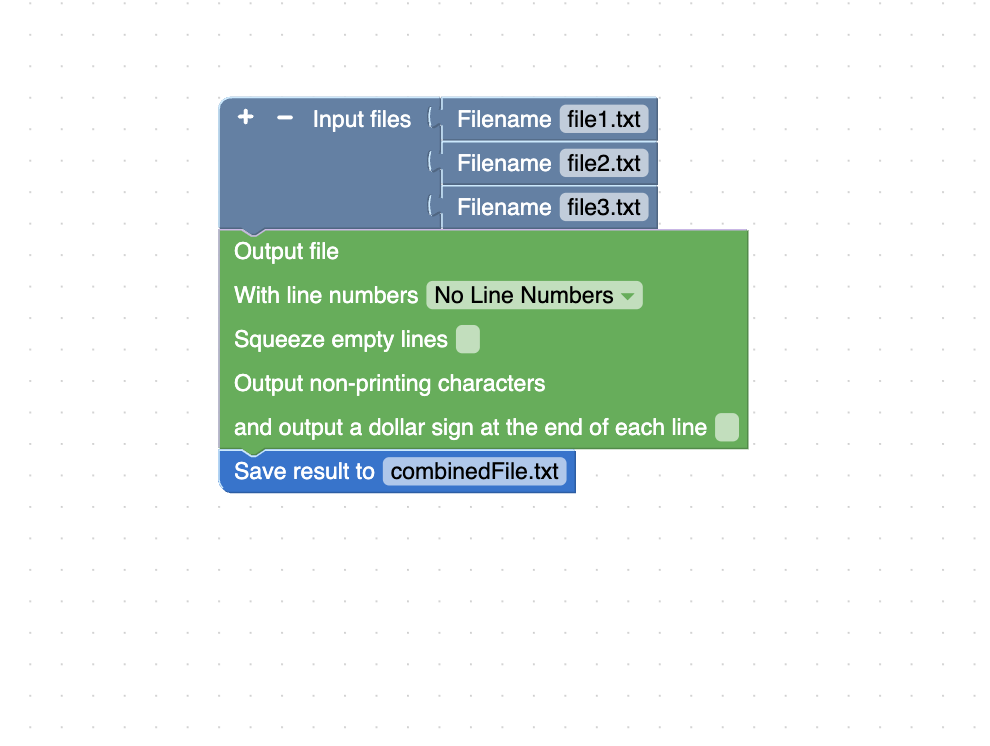
The corresponding Unix command for this task is: cat file1.txt file2.txt file3.txt > combinedFile.txt
-
Extracting Specific Columns from a File and Saving to a New File
Extract columns 1 and 3 from a CSV file and save the output to a new file.
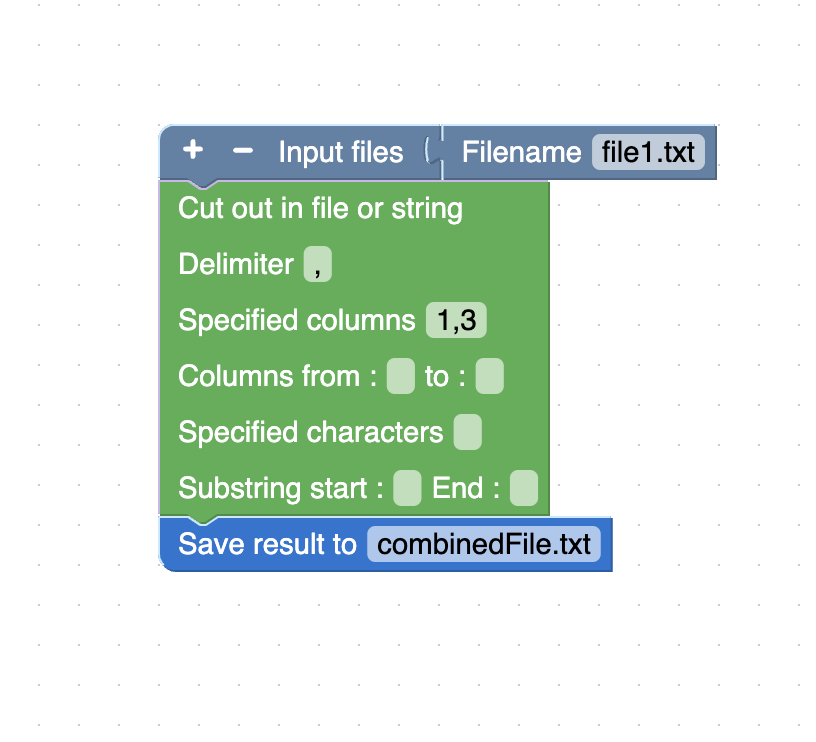
The corresponding Unix command for this task is: cut -d ',' -f 1,3 file1.txt > combinedFile.txt
-
Summing Annual and Total Sales from a Text File Using awk
Use the awk command to calculate the sum of sales for each year and the total sales across all years from a .txt file.
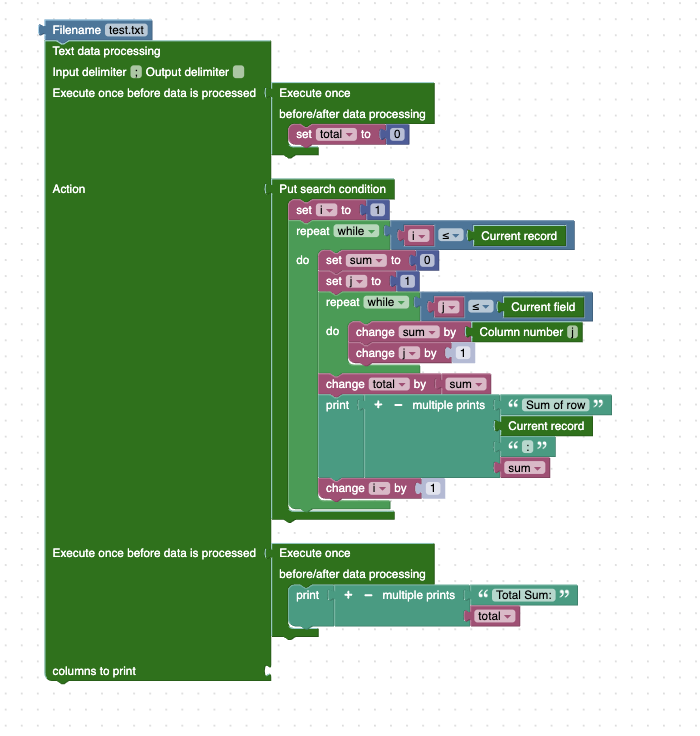
The corresponding Unix command for this task is: awk -F ';' ' BEGIN {total = 0; } {i = 1; while (i <= NR) { sum = 0; j = 1; while (j <= NF) { sum += $j; j += 1; } total += sum; print "Sum of row", NR, ":", sum; i += 1; } } END {print "Total sum:", total; } ' sales.txt
-
Find Maximum and Minimum Values
Find the highest and lowest temperatures from a weather log (weather.log) where temperatures are in the 3rd column.
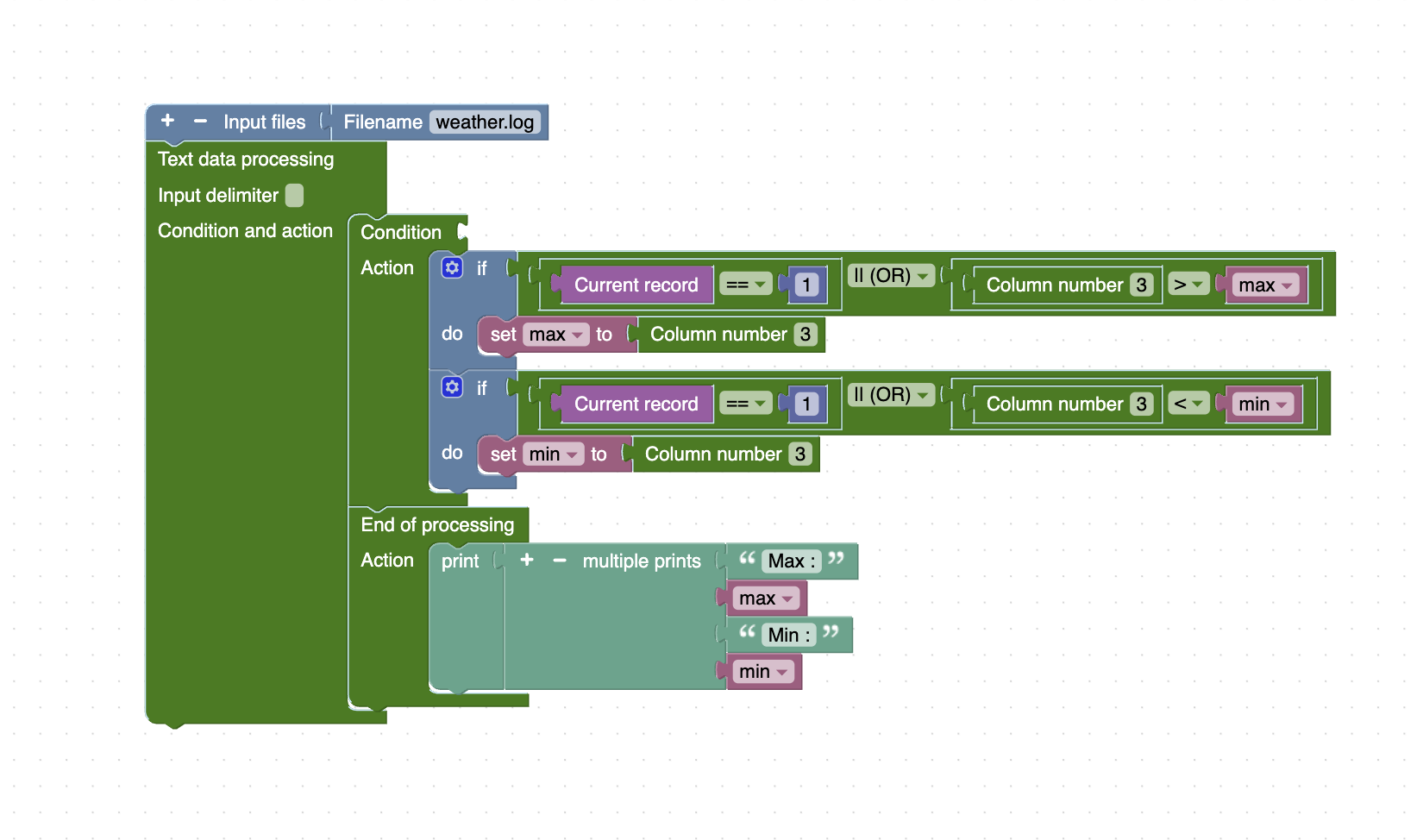
The corresponding Unix command for this task is: awk ' {if (NR == 1 || $3 > max) {max = $3; } if (NR == 1 || $3 < min) {min = $3; } } END {print "Max :", max, "Min :", min; } ' weather.log
-
Modify timestamp in existing files
Modify the last modification timestamp in existing files to the specified date and time. If the file does not exist, do not create a new file.

The corresponding Unix command for this task is: touch -c -m -d 2024-11-27T21:55:24 arg1 arg2 arg3